TorQ TAQ – a NYSE TAQ Loader
Robert Sketch
The TorQ-TAQ Loader architecture is an extension to TorQ, which efficiently downloads TAQ files directly from the NYSE website. This blog explains the following:
- What is NYSE TAQ?
- The types of files which TorQ-TAQ supports
- A brief overview of each file type
- Goals which we hope to achieve with TorQ-TAQ
- TorQ-TAQ Architecture description
- TorQ-TAQ message flow
- Support and Custom Configuration
What is NYSE TAQ?
NYSE TAQ, as defined on the NYSE website, is a set of files that contain all trades and quotes for all issues listed and traded on US regulated exchanges for a single trading day. The historical database dates back to 1993 and is available for download.
TorQ-TAQ Supported Files and Specification
This section will go into more detail about the file types that TorQ-TAQ currently supports. A more detailed explanation of the TAQ files can be found directly on the NYSE website.
Three files are currently supported: trade, quote, and national best bid offer (nbbo). These files have the form:
- EQY_US_ALL_TRADE_YYYYMMDD.gz (trades)
- EQY_US_ALL_NBBO_YYYYMMDD.gz (National Best Bid Offer)
- SPLITS_US_ALL_BBO_*_YYYYMMDD.gz (Best Bid Offer – 26 files per day)
Some simple file statistics can be seen in the figure below. These have been taken directly from the NYSE TAQ file documentation:
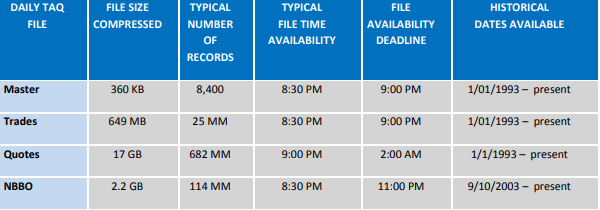
It is important to note that for the quote file statistics, this is for all 26 split files (A-Z) combined and not indicative of what a single split file contains.
TorQ TAQ Goals
Development of TorQ-TAQ has the following notable aims:
- The Loader should be TorQ based
- The loader is capable of using all functionality that currently exists in TorQ
- Loading files can be multi-threaded
- If a system has multiple cores available, then the loader supports loading TAQ files in parallel for faster loading times
- Load TAQ files using the streaming decompress algorithm with .Q.fpn
- We use the
.Q.fpnstreaming decompress using named pipes in order to avoid decompressing data to disk in order to complete a load
- We use the
- Splitting up responsibilities of loading the file with different processes
- Developing with support considerations
- Monitoring statistics exist in each of the processes to evaluate which files have been successfully loaded and why some loads might have failed
Architecture
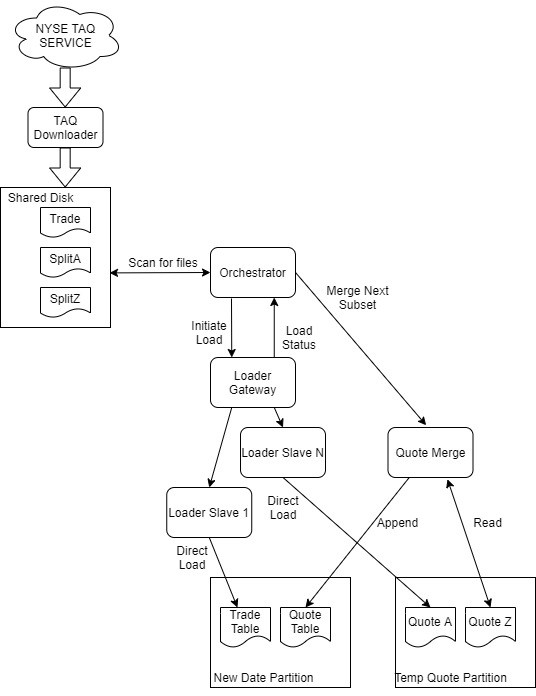
We will first give a brief overview of each process in the TorQ-TAQ architecture and its responsibilities, then we will give a brief discussion on the message flow depicted in the image below.
Processes
Orchestrator: Responsible for checking when the TAQ data arrives, initiating loads upon the data’s arrival, ensuring data is merged, and moving data to the proper HDB when all loads are complete. In addition, the orchestrator is in charge of keeping up with various monitoring statistics. These statistics include load start times, end times, an indicator variable showing if the load was successful or not, and error logging for if a process fails.
Loader gateway: A standard TorQ gateway. TorQ Gateway documentation can be found here.
Loader Workers: These processes are responsible for executing loads. Multiple loader processes exist to allow loads to run in parallel.
Merger: The quote merger is the process which will merge all 26 split files as they are loaded. Once all split files are successfully loaded and merged, this process moves all data to the HDB.
Message Flow
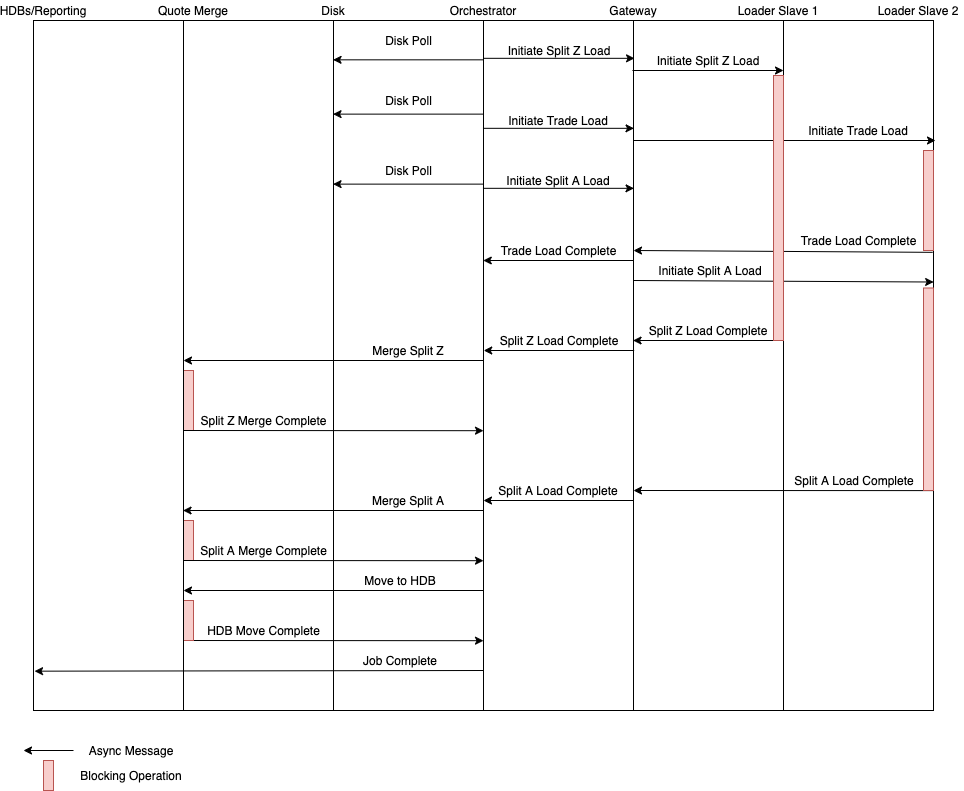
TorQ-TAQ begins at the shared disk below the TAQ Downloader as seen on the architecture figure. The downloader process is still a work in progress and is part of future development.
Currently, the user must first download TAQ .gz files to a directory on disk called filedrop in the upper-level TorQ directory. At this point, the orchestrator will recognise a new file exists in this filedrop directory and invoke a loader process. If the user can utilise multiple loader slaves, then if more than one TAQ file is recognised and more than one loader process is available, then files will be loaded in parallel.
Depending on if the file recognised is a trade, quote or nbbo file, the way the data is saved behaves differently.
- Trade/NBBO: Data is loaded to a temporary hdb, located in
deploy/tempdb/final/YYYY.MM.DD/tradeOrnbbowhere deploy is the top-level directory of the TorQ stack. - Quote: Data is loaded to
deploy/tempdb/quote*/YYYY.MM.DD/quote/
By default, when Trade/NBBO data is loaded to the temporary HDB, it lives in the deploy/tempdb/final/YYYY.MM.DD/ directory until all data from this day has been loaded. When quote data is loaded, it is saved in the tempdb directory but saved as a partition of the quote split file that is being loaded (quoteA, quoteB, quoteC etc.).
When the quote split file has been loaded successfully, it is merged using the merger process. This merger process merges the quote split file to the same location as the trade and/or nbbo data in deploy/tempdb/final/YYYY.MM.DD/quote. The split files do not have to be loaded in alphabetical order; i.e., split file B can be loaded and merged before split file A.
When the trade, nbbo and all 26 quote split files have been successfully loaded and merged, the orchestrator then calls the merge process to call the function which moves all of the loaded and merged data to the final hdb in its relevant date partition.
All IPC uses asynchronous messaging and uses the standard TorQ gateway and discovery processes to know which processes are available for loading and merging. Specification on these processes can be found in the TorQ documentation.
Support and Monitoring
We have added monitoring statistics for each load attempt in the orchestrator. A snapshot of what this table contains for each load attempt can be seen below:
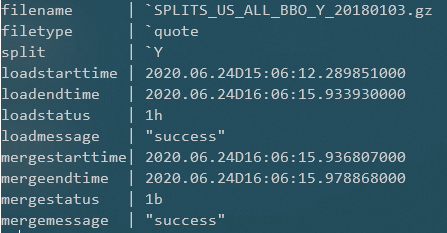
loadid– Unique ID for each load attempt.filename– Name of the .gz file to be loaded.filetype– Type of file, i.e. trade, quote, or nbbo.split– If the file is a quote, this will display the split letter.loadstarttime– Time at which the load started.loadendtime– Time at which the load completed.loadstatus– Binary indicator showing if load was successful (takes value 1) or unsuccessful (0).loadmessage– Displays the error message if the load was halted by an error, shows “success” otherwise.mergestarttime– If the file is quote, this will display the start time of the merge.mergeendtime– Time at which the merge of the split file is completed.mergestatus– Binary indicator showing if the merge was successful (takes value 1) or unsuccessful (0).mergemessage– Displays the error message if the merge was halted by an error, shows “success” otherwise.
Support Functionality
We have added functionality to allow more flexibility about when you move loaded final data to the HDB, and to specify which files you are interested in loading. Meaning, you might specify you only want to load trade and quote data and not nbbo, or some other combination.
We have included a function called manualmovetohdb – This function can be called with arguments [date;filetype] in the orchestrator to manually move loaded data to the hdb. date is a date atom and filetype is a symbol or list of symbols (any of trade, quote, or nbbo). By default, data is only moved when all files have been successfully loaded and merged. However, this can be called to move the data at a different point in time.
Conclusion
TorQ TAQ improves the speed and efficiency at which NYSE TAQ files are loaded with a focus on support considerations. If you interested in improving your current TAQ loader, please contact us at info@aquaq.uk.
Share this:











