Recovering Corrupt Tickerplant Logs
Glen Smith
Corrupt tickerplant logs are a curse that no one deserves but that doesn’t stop them from happening even to the best of us. However, all hope is not lost as it is possible to recover the good messages and discard the bad. In this post we will extend upon the standard rescuelog procedure to recover as much as possible from the log file.
What is a tickerplant log?
Once the feedhandler publishes data to the tickerplant, the tickerplant will write this data to the log, which is a binary file, and then publishes the data to its subscribers. The log is used for failure recovery, so if the RDB fails it has a copy of the days data on disk which it can then recover from. For this reason the tickerplant log file is extremely important and must be available at all costs so it is not of much use if it becomes corrupt. The main causes of corruption are:
- The system crashing mid write
- The disk filling up
Further information on kdb+tick can be found here.
When default functionality won’t work.
The -11! function, which is used to replay tickerplant log files will refuse to execute the file as soon as it encounters the first corrupt message, emitting a “badtail” error message. This is fairly limiting if you consider the hypothetical case of 1 corrupt message in the middle of 1 million uncorrupted messages. When the -11! function is provided with an additional argument -2, it will return the amount of valid clunks in the log file from the start of the file along with the size of the data in bytes if the file is corrupted. Any non-corrupt file will just return the number of messages. This provides some useful diagnostic information about the file before we begin to repair it. The standard way to recover a tickerplant log file is to read the messages to the first bad message, and discard the rest.
How to repair it?
For our hypothetical corrupt file let’s assume that the corrupt messages lie somewhere in the middle of the file and to solve this problem we need to get rid of these corrupt messages. The problem becomes simpler if you consider splitting the file into different messages by checking if a particular byte sequence which represents the message header is present and then checking whether the messages are corrupt. Once this process is complete the good messages are written to an uncorrupted tickerplant log file. This process is repeated consecutively over the tickerplant log file from the beginning to the end.
Luckily this functionality has already been created and is included in the latest version of TorQ and is located in the “tplog” namespace. It will check the log by performing an integrity check, return diagnostic messages and will write uncorrupted messages to a new log.
The code to repair the log file is below, taken from the code/common/tplogutils.q file. All the hard work is performed by the repairover function which is shown below. It is called by the repair function using the over operator to consecutively repair each message of the log data, with the start position being increased each time until it reaches the end of file. The result is a modified tickerplant log that contains only the good parts. This code is already documented step by step but I will comment on the cool parts.
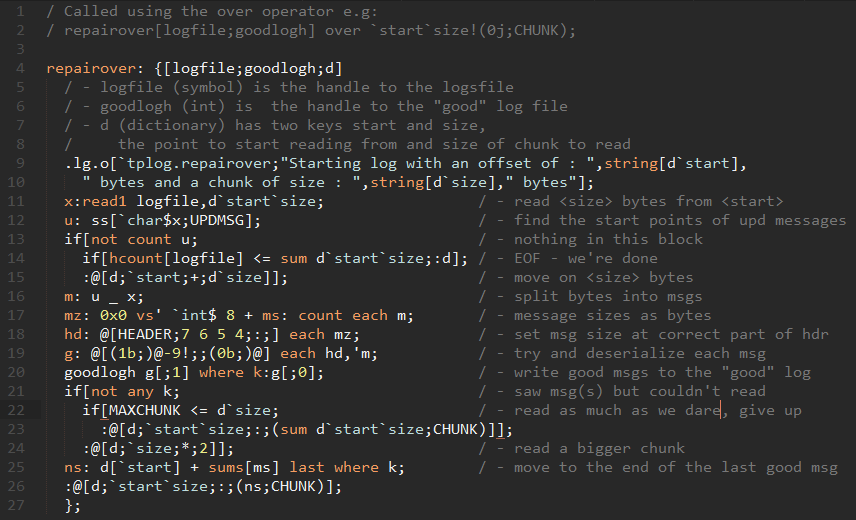
Screenshot of repairover code used in the tplogutils.q file. Image used for formatting.
Byte manipulation
To search and manipulate the corrupted tickerplant log, byte manipulation is used. A chunk of the file is read in as bytes using the read1 function. First point of order is to find the index of the upd messages, which is done by casting the bytes as chars and then searching using the constant, UPDMSG.The UPDMSG is a char token used to search the log for calling of the upd function. This index is used to split the bytes into their individual messages and the byte size of each message is stored. A new header of each message is built by replacing elements of the HEADER constant with the message size bytes. These modified headers are joined to each message and then deserialisation is attempted. These messages are then added to a list along with a check digit indicating whether it was successfully deserialised. The corrupted messages are filtered out whilst the good messages are written to a good log file.
Conclusion
Hopefully this will have been of some use, or you can bookmark it and use it to dig yourself out of a hole at some point. If you need any help with any aspect of kdb+, please don’t hesitate to contact us.
Share this: