Data Intellect
In a typical kdb+ system, there are several q processes running concurrently. These will commonly include services such as a Real-Time Database (RDB), which contains today’s or recent information in memory, or a Historical Database (HDB), which stores information from previous days. The client can have the ability to access these directly, but in some cases these services are hidden in the background and access to them is provided by a gateway.
The gateway normally includes a set of custom functions designed to access the data and perform queries in the most efficient manner. This important feature introduces a layer of separation between the client and the data, meaning that it cannot be accidentally tampered with, and it may provide a level of security by performing checks on user entitlements before a query is made.
A gateway can also be capable of performing aggregations on different sets of data. Say we wanted to perform a particular query for the last week, the gateway could access the HDB and RDB and combine this information. Advanced gateways are capable of parallelism, whereby they are capable of performing more than one operation simultaneously, which allows scaling of the numbers of processes and clients. Fault tolerance is built-in, if a server becomes inoperative the gateway can pull data from another source, without the user being aware that a process is not functioning.
[custom_headline type=”left” style=”margin-top: 0;” level=”h4″ looks_like=”h4″]Synchronous/Asynchronous[/custom_headline]
Gateways may be synchronous or asynchronous. The former means that the client must have received a reply from the gateway before the next client request can be accepted. Asynchronous gateways remove this constraint, allowing for quicker processing of multiple operations. An asynchronous setup works by permitting operations to be performed on data at the same time that other sets of data are being processed or transferred.
As a synchronous setup means that the gateway will spend a lot of time being idle whilst it waits for a response, asynchronous is the preferred method. The primary advantage in this case being that more than one client query can be performed at once. It does however involve another layer of complexity. Each request must be tagged with an identifier which gets passed to and from all the involved services. This allows the gateway to keep track of queries that are to be performed, and those whose results are to be returned to the user. This is shown in the diagram below, where the numbers indicate the order of information flow around the system.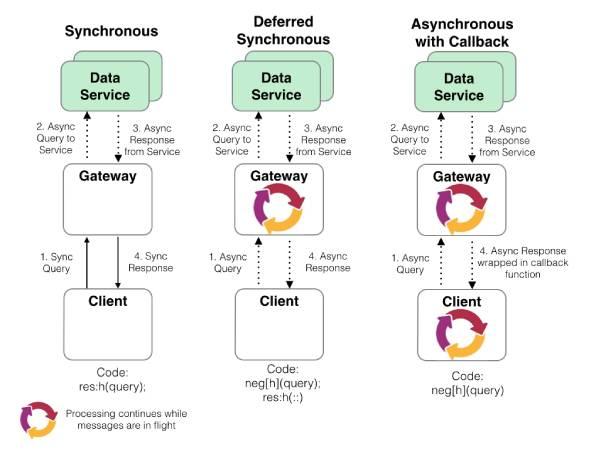
[custom_headline type=”left” style=”margin-top: 0;” level=”h4″ looks_like=”h4″]Load Balancing[/custom_headline]
A large number of requests will bring about the need for load-balancing functionality within the gateway. Essentially this kind of gateway is comprised of a server and multiple slave-servers. When requests are delivered to the gateway, it chooses which slave-server to process the request on, based on which is free at the time. If all are occupied, the request is queued in the gateway until one becomes free. This method is an efficient way of handling large numbers of simultaneous requests, however it will only be beneficial if asynchronous requests are made. 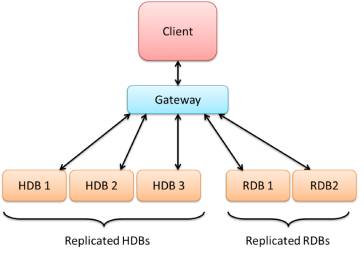
Example code demonstrating how load-balancing operates can be seen at mserve.q from kx systems.
[custom_headline type=”left” style=”margin-top: 0;” level=”h4″ looks_like=”h4″]Fault Tolerance[/custom_headline]
If some part of the system were to fail, the gateway can be set up to activate levels of redundancy, such as replicated services running on additional backup servers. The following diagram illustrates how this might work in a real load-balancing setup. The gateway recognises that one of the replicated HDB processes has failed, and no longer routes queries to that source.
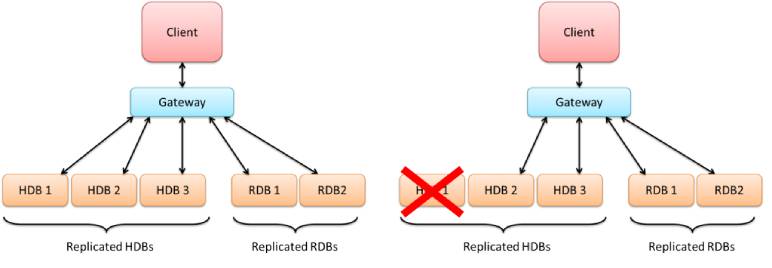
Another, more complex possible scenario is the situation where there are entirely separate systems that use replicated processes. The gateway can be configured to reach across to another system and begin to pull that data in. This is shown in the images below, with two separate systems running in a hot-hot configuration in separate data centres.
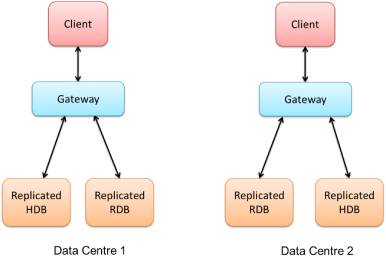
If the first Data Centre’s RDB were to stop working for any reason, the gateway can be configured to automatically transfer over to the backup, and begin performing queries and returning information from there.
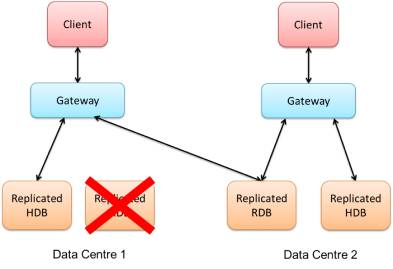 This process should hopefully present a seamless user-experience for the client, who needn’t know that a failure has occurred. This also provides time for system administrators to work on fixing the back-end. A caveat to this kind of setup is that there needs to be sufficient network bandwidth for transferring data over a Wide Area Network (WAN).
This process should hopefully present a seamless user-experience for the client, who needn’t know that a failure has occurred. This also provides time for system administrators to work on fixing the back-end. A caveat to this kind of setup is that there needs to be sufficient network bandwidth for transferring data over a Wide Area Network (WAN).
[custom_headline type=”left” style=”margin-top: 0;” level=”h4″ looks_like=”h4″]Aggregation[/custom_headline]
Ideally, aggregative operations would be performed by the service being requested. This speeds up operations by allowing for as little unnecessary data-transfer as possible. Often data will need to be re-aggregated at the gateway level.
Here is one aggregation example where monthly trading volumes are calculated from information held on the RDB and HDB:
HDB:
q)hdbdata:select sum size by sym,date.month from trade where date.month >= -3 + `month$.z.d
sym month | size
------------| ------
AAPL 2015.12| 593144
AAPL 2016.01| 912510
AAPL 2016.02| 220911
CSCO 2015.12| 935629
CSCO 2016.01| 740497
CSCO 2016.02| 894658
DELL 2015.12| 139615
DELL 2016.01| 568691
DELL 2016.02| 110362
GOOG 2015.12| 490130
GOOG 2016.01| 161822
GOOG 2016.02| 188170
RDB:
q)rdbdata:select sum size by sym,`month$.z.D from trade
sym month | size
------------| -----
AAPL 2016.02| 26929
CSCO 2016.02| 93878
DELL 2016.02| 96708
GOOG 2016.02| 50088
/-Then at the gateway level:
q)hdbdata+rdbdata
sym month | size
------------| ------
AAPL 2015.12| 593144
AAPL 2016.01| 912510
AAPL 2016.02| 247840
CSCO 2015.12| 935629
CSCO 2016.01| 740497
CSCO 2016.02| 988536
DELL 2015.12| 139615
DELL 2016.01| 568691
DELL 2016.02| 207020
GOOG 2015.12| 490130
GOOG 2016.01| 161822
GOOG 2016.02| 238258 This method reduces the amount of data passed around the system, with each service returning an aggregated data set as opposed to raw data being returned to the gateway from both services and the aggregation performed.
[custom_headline type=”left” style=”margin-top: 0;” level=”h4″ looks_like=”h4″]What We Offer[/custom_headline]
The open source TorQ framework package offered by AquaQ includes a feature-rich gateway that includes all of the features described above and more. Synchronous and asynchronous queries are fully supported. The gateway also incorporates an efficient load-balancer removing the need for a separate load-balancing service. Queue prioritisation algorithms can be easily added. As with all kdb+ processes, APIs for Java, C# and C are officially supported by Kx Systems with other interfaces available.
Share this: