Jamie Grant
We’ve noticed a few clients and listbox/google group members asking questions about Apache Kafka recently, so we decided to take a closer look and add it to TorQ.
Apache Kafka bills itself as a ‘distributed streaming platform’ – what that seems to mean is that it is a real time messaging system with persistent storage in message logs. The distributed part of the description means it can run in a cluster which gives it scalability and fault tolerance. It was developed at LinkedIn and open sourced in 2011.
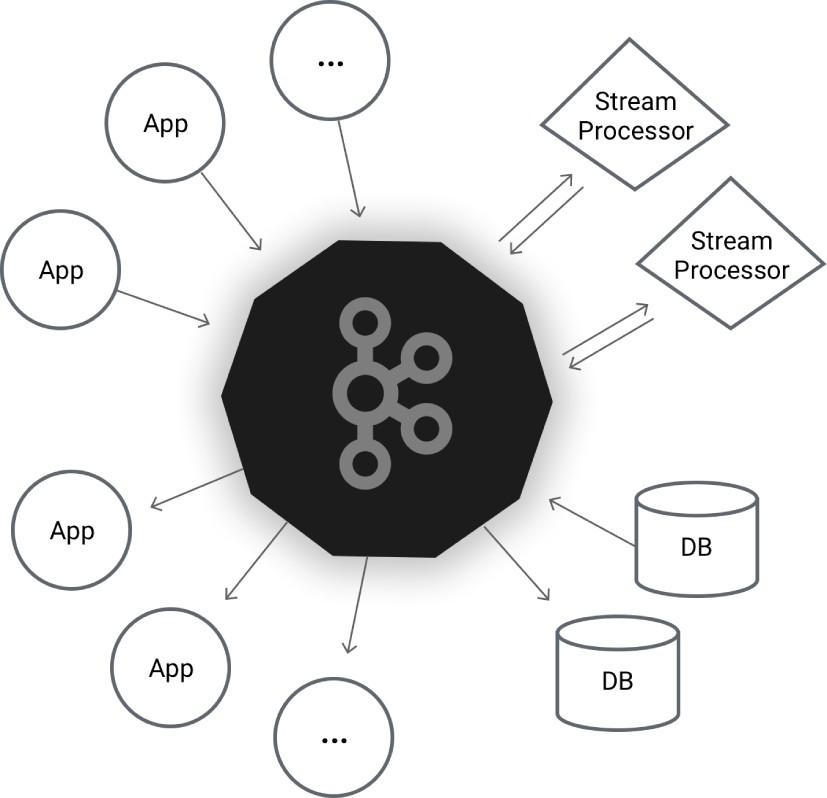
Kafka & kdb+ Use Cases
The core functionality of Kafka – pub/sub messaging with persisted logs, will be familiar to most readers as the functionality offered by the kdb+ tick tickerplant. The tickerplant log allows the real time database and other consumers to replay a day’s events to recover state. An application architecture built around Kafka could dispense with a tickerplant component, and have RDBs and other real time clients query Kafka on startup for offsets, and play back the data they need. While not suitable for very low latency access to streaming data, it would carry some advantages for very high throughput applications, particularly those in the cloud:
- Kafka’s distributed nature should allow it to scale more transparently than splitting tickerplants by instrument universe or message type
- Replaying from offsets is the same interface as live pub/sub and doesn’t require filesystem access to the tickerplant log, so RDB’s and other consumer could be on a different server
kafkaq
Apache Kafka is java based, but there is a mature open source C library librdkafka which allows us to build native bindings to q via a shared library. We’re releasing this today in it’s current form, with basic pub/sub functionality from q to Kafka.
Roadmap
There are a few features we plan to add in the near future:
- Subscribe from offset
- Balanced consumer groups
- Delivery callbacks for producers
- SSL support
One of the reasons we’re releasing it in an Alpha state is that we’re really interested in hearing from current users of both kdb+ and Kafka, so we can get feedback on what essential features the library should have to get the most out of both technologies.
If you’re an Apache Kafka user and this interests you – please get in touch with us at info@aquaq.co.uk
Share this:











