Faster Recovery with kdb+ tick
Jonathon McMurray
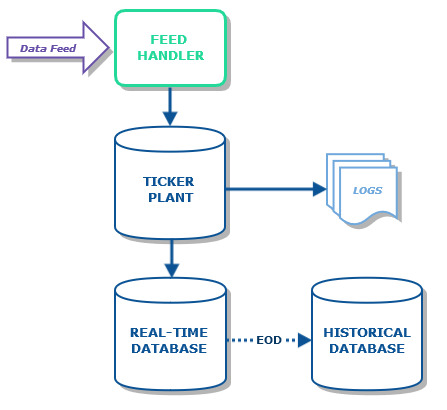
The standard tickerplant (tick.q) from kdb+tick receives updates from feeds and pushes these updates to subscribing processes, as well as writing them to the log file. The tickerplant (TP) will count the number of messages received from the feed and written to the log file (in a variable .u.j) as well as the number of messages pushed to subscribers (in a variable .u.i). The counts are used for recovery purposes – if a subscribing process wishes to recover it can request the location of the TP log file and the count, and replay the log file up to the specified count.
The recovery mechanism is excellent for ensuring that the recovering process does not receive any duplicated data or miss any data. However, the downsides are:
- each subscribing process must have access to the filesystem the TP stores the log on
- replaying the log can be time consuming
The counts are the number of messages, rather than the number of records processed, and are also not separated by table. If the number of records processed per table were tracked instead, a new subscribing process would be able to get these numbers and perform a query against the real time database (RDB) for those records, rather than replaying the log file. This assumes that the RDB is a standard configuration, where the RDB stores all the updates from the tickerplant.
This is particularly advantageous when the TP is handling updates for multiple tables and the subscriber is interested in only one of these tables. Rather than having to replay the TP log file, which contains messages concerning all tables, the process can simply subscribe to the TP for updates on the relevant table, and then query the RDB for the relevant records pushed before subscription. It also means that the subscribing process does not need to have access to the same filesystem as the TP – subscribers can be distributed across machines.
This has been implemented in TorQ in the form of two dictionaries, .u.icounts and .u.jcounts, analagous to .u.i and .u.j respectively. These dictionaries track, per table, the number of records received by the TP and written to the log file (in .u.jcounts) and pushed to subscribers (in .u.icounts). When subscribing, a subscriber can request the .u.icounts dictionary, retrieving the number of records pushed to each table prior to subscription. For example:
icounts: t”.u.sub[`;`];.u.icounts”where t is an open handle to a TP process. Here, the local dictionary “icounts” will contain the counts of records in each table at the time of subscription, and the process will be subscribed to the TP.
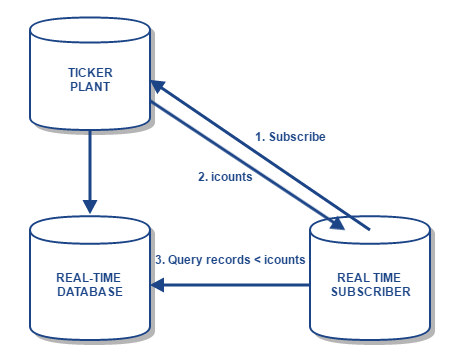
It should be noted that in order to implement these dictionaries in the TP, it was necessary to replay the log file while starting the TP (so as to count individual records), rather than simply counting the messages in the log as before. Therefore, the start-up time of the TP is increased. In testing, the initial start-up time was found to be approximately 100{e673f69332cd905c29729b47ae3366d39dce868d0ab3fb1859a79a424737f2bd} longer than the original method. Additionally if the TP log suffers from a bad tail (i.e. is corrupt) then the start up will take approximately three times as long as before. The assumption is that intraday TP restarts with large log files are rare events.
There is also a small increase to the code running upon receiving updates at the TP, to count the rows in each message and update the appropriate dictionary accordingly.
Below is a short example of a subscriber connecting to the TP and RDB, subscribing to updates from the TP, and keeping a record of the sum of “size” for each sym in the “trade” table:
// open handle to TP
t:hopen[`::7420];
// define upd function and table for sums
sumstable:([sym:`$()] sumsize:());
upd:{[t;x] if[t=`trade; sumstable+:select sumsize:sum size by sym from x]};
// subscribe to TP and get icounts
icounts:t".u.sub[`trade;`];.u.icounts";
// open handle & recover historic data from RDB
r:hopen[`::7422];
sumstable+:r({select sumsize:sum size by sym from trade where i<x};icounts[`trade]);This example demonstrates how a subscriber can use the icounts dictionary to pull the necessary data from the RDB, rather than replaying the entire log file to retrieve only the updates to the trade table. It should also be noted that for a recovery as demonstrated here to work correctly, the RDB must contain all data from today (i.e. no missed updates), and only today’s data, otherwise incorrect data will be recovered from the RDB. Both of these assumptions are the regular approach for kdb+ tick based data capture environments.
If you want to know more or are having data capture architecture issues, please get in touch.
Share this:












