Avoiding End-of-Day Halts with TorQ
Data Intellect
kdb+tick is great, but there’s a problem- when the RDB (real time database) writes to disk on its daily schedule, users cannot access that day’s data until the write out is complete. There are various solutions to this issue including:
- using something similar to w.q to write out the data periodically intraday
- have a replicated system and staggering the save down, routing all user queries to a single system while the other saves down
- ensure that no critical client processes rely on the RDB being available during the save down processes, offloading critical functionality to dedicated processes
We’ve added our own version to TorQ. It’s based on the w.q approach, but with a few modifications. The process architecture looks like this:

The RDB receives data from the tickerplant as usual. The WDB process also receives data from the tickerplant and persists it to disk periodically throughout the day, usually to a separate temporary directory away from the main HDB directory. At end-of-day, the Sort process resorts the data on disk and moves it the HDB directory. The Sort process is then responsible for reloading each of the other processes. The sorting is offloaded to a separate process to avoid the additional end-of-day problem of “tickerplant back-pressure” – this is when the tickerplant memory usage builds up as it is trying to push data to a process which is blocked (i.e. doing something else). In the architecture above, neither the RDB or the WDB are blocked for a significant period at end-of-day.
When the Sort process executes the reload command in each of the affected processes it uses async messages and aims to minimize the period where the data may be available in two places at once (i.e. the new day’s data is available in both the RDB and HDB). It asynchronously sends a reload request to each affected process, and forces the process to call back asynchronously to the Sort process, and wait to be released by the Sort process. Once all the processes have called back (or a specified timeout period has expired) the Sort process releases all processes simultaneously. This sequence of calls is wrapped in a start/end message sent to the gateway(s).
The sequence of calls and reload messages at end-of-day looks like this:
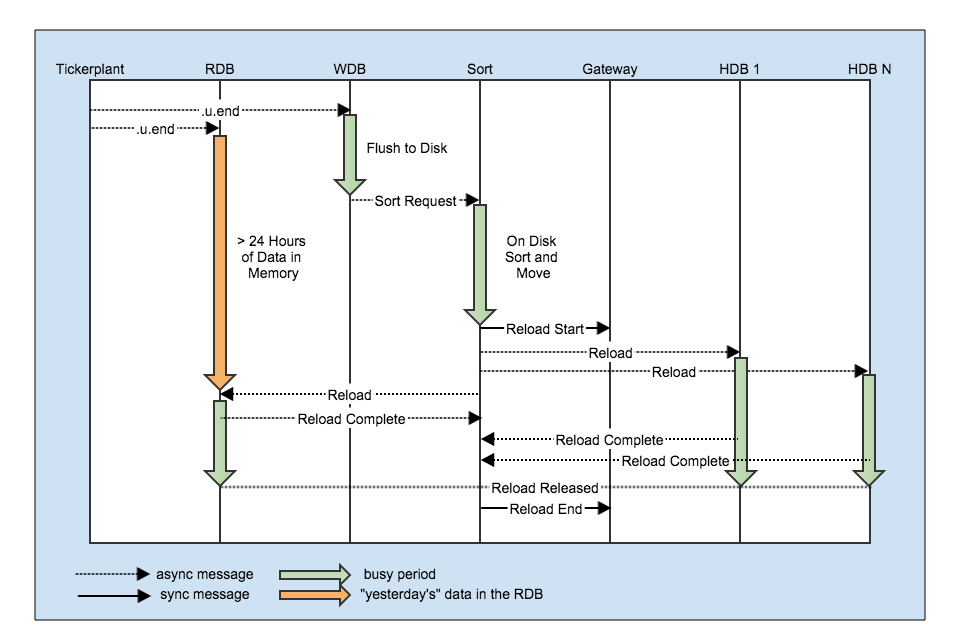
The crux of this approach is that the data is available for users to query in the RDB until it is available in the HDB, and the system is not reliant on the RDB to persist data to the disk. To a certain extent the length of time required to flush and sort the data is irrelevant. However, with this being kdb+, that attitude is never going to wash so it should be noted that the on-disk sort can be time consuming (as the data is essentially re-written to disk) and may end up taking longer than the standard approach of writing directly from the RDB. We investigated some other approaches including writing the data to an intraday sym partitioned HDB and stitching them together at end-of-day but settled on the above as it is simpler and more general- we don’t have to make assumptions about the final sort order or the cardinality of the data.
Removing the requirement of the RDB to persist data to disk has some additional extra benefits:
- the memory usage of the RDB may reduce: there can be a spike in RDB memory usage at end-of-day during the save to disk
- there may be tables which are sent to the RDB for persistence but not actively queried intraday (e.g. tables used in a research context only). These can be dropped from the RDB subscription list, reducing system memory usage
- it is easy to replicate the RDB process as you don’t have to worry about the replicated processes co-ordinating the end-of-day save between themselves
Data Synchronization
There are no data synchronization issues in a standard kdb+tick setup. The RDB writes the data out and then notifies the HDB that it is available with a synchronous call. Once the RDB becomes available again to serve client queries it no longer contains “yesterday’s” data which is now available in the HDB.
Our approach does have a synchronization issue- it may be possible that “yesterday’s” data is available both in the RDB and HDB, which can make joins across the two processes via the gateway return incorrect results. We have aimed to minimize this by ensuring that when the processes are reloaded they are made available “simultaneously” (or as close as we can make it). However, given the asynchronous nature of the TorQ gateway, it may be possible to get incorrect results. We have a solution in development which will ensure clients don’t get back incorrect results – it will be in the next release.
It All Looks A Bit Complicated
Well … yes. It’s certainly more complicated than kdb+tick, and extra complexity is rarely a good thing. The above set up is a suggestion, and it’s what you get when you run the the TorQ Finance Starter Pack. It’s easy to switch back to the standard model where the RDB saves the data to disk – just set the reloadenabled variable to 0b in the RDB. You can also run the system without the sort process (the wdb and sort processes run the same code- if the wdb doesn’t find a sort process, it will just sort and move the data itself).
We would welcome any comments / suggestions / enhancements to our setup.
Share this: