Level 2 Storage Formats
Data Intellect
Storing an order book can be tricky due to the large number of orders and prices that continually change throughout the day. Here we investigate and compare three common methods of storing an order book, assessing their benefits and limitations. To do that, the TorQ-CME pack was used to process CME MDP 3.0 FIX data on Soybean Futures for 10 syms, with up to 10 price levels of depth.
Raw quotes
The first table provided by TorQ-CME, rawquote, gives the flow of orders throughout the day, summarised by how they affect price levels.
q)select from rawqoute where Symbol=`ZSQ6, TransactTime within (05:00;05:01)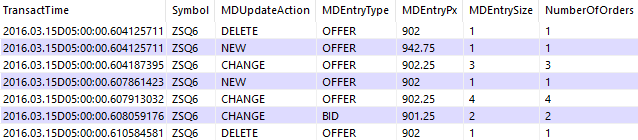
Each row corresponds to an action for a price level, whose side (BID or OFFER) is stated by the MDEntryType column. There are 3 possible actions, given by the MDUpdateAction column:
- NEW – Add a new price to the book
- CHANGE – Modify the size of an existing price. The MDEntrySize given represents the new total size for that price
- DELETE – Remove a price from the book (through cancellation or trade execution)
The NumberOfOrders column tells us how many individual orders make up each price level. It is also common to track these individual orders instead of aggregating them by price level. This has the advantage of being able to trace how long an order spent in the market, through its order ID. Viewing orders aggregated by price level is known as Level 2 Data, while keeping track of individual orders is referred to as Level 3. A visual explanation of the different levels can be seen here.
Taking into account that updates can arrive in batches, we can easily see how many times the order book changes throughout the day.
q)count rawquote
1179899
q)sum select bookchanges:count distinct TransactTime by Symbol from rawquote
bookchanges| 845673
q)select count distinct TransactTime by Symbol from rawquote where Symbol=`ZSQ6
Symbol| TransactTime
------| ------------
ZSQ6 | 56304
q)select count distinct TransactTime by Symbol, MDEntryType from rawquote where Symbol=`ZSQ6
Symbol MDEntryType| TransactTime
------------------| ------------
ZSQ6 BID | 28957
ZSQ6 OFFER | 27404Notice that the bid and ask books for ZSQ6 together changed a total of 56361 times, meaning that there were only 57 times throughout the day when the bid and ask books changed at the same time, which is quite typical.
To see the full order book at a particular time, we can first get the latest orders for each side and price, then remove the deletions to get the state of every open price level.
q)openorders:delete from (select by MDEntryType, MDEntryPx from rawquote where Symbol=`ZSQ6, TransactTime<=16:00:00) where MDUpdateAction=`DELETE
The bid and ask books can then be obtained by splitting and reordering in ascending price level order, making sure that no more than 10 levels are taken.
q)select[10;> MDEntryPx] from openorders where MDEntryType=`BID / bid book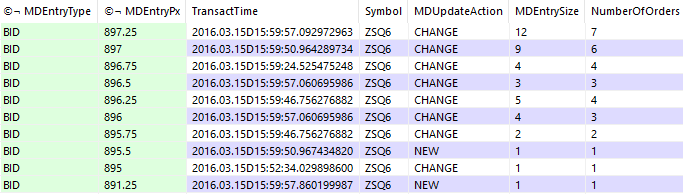
q)select[10;< MDEntryPx] from openorders where MDEntryType=`OFFER / ask book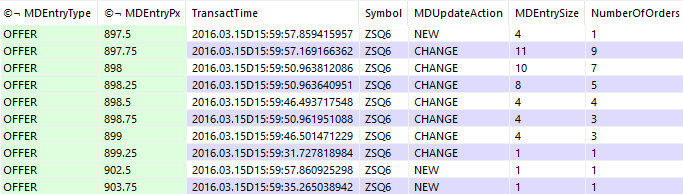
While this gives the full book at a point in time without too much difficulty, seeing how the book changes throughout the day is not as straightforward. Suppose we want to see all the transitions for the best bid and asks, which is also known as the Top of the Book, or Level 1 Data. A naive approach would be to replicate the above method and recalculate the full book at each time point. It is much quicker to instead build the book throughout the day on a quote-by-quote basis.
// Returns time series of best bid and asks
getbooktop:{[tab]
// Updates book with new quote and takes no more than 10 levels
addqt:{[bk;px;typ;size;action]
$[action=`DELETE; delete from bk where MDEntryPx=px, MDEntryType=typ;
action=`CHANGE; bk upsert (typ;px;size);
[bk:bk upsert (typ;px;size); (select[10;> MDEntryPx] from bk where MDEntryType=`BID), select[10;< MDEntryPx] from bk where MDEntryType=`OFFER]]
};
// Create table of book snapshots
bk:([MDEntryType:`symbol$(); MDEntryPx:`float$()] MDEntrySize:`float$());
bk:update bksnap:addqt\[bk;MDEntryPx;MDEntryType;MDEntrySize;MDUpdateAction] by Symbol from tab;
bk:`TransactTime`Symbol`bksnap#0!select by Symbol, TransactTime from bk;
// Returns top of book snapshot (including nulls if one side is missing)
pulltop:{[bk]
b:raze exec first each (MDEntryPx;MDEntrySize) from bk where MDEntryType=`BID, MDEntryPx=max MDEntryPx;
a:raze exec first each (MDEntryPx;MDEntrySize) from bk where MDEntryType=`OFFER, MDEntryPx=min MDEntryPx;
b,a
};
// Join each top snapshot with time and sym and remove duplicates
topofbk:([] bestbid:`float$(); bestbsize:`float$(); bestask:`float$(); bestasize:`float$());
topofbk:(`time`sym xcol -1_'bk),' topofbk upsert (pulltop 0!) each bk`bksnap;
select from topofbk where any differ each (sym;bestbid;bestbsize;bestask;bestasize)
};A column was added to rawquote containing tables of book snapshots, which were updated with each quote. The best bid and asks were then taken from the last table in each batch of updates. A similar approach can be used when working with Level 3 Data, using order ID as a key in each book snapshot instead of price.
q)\ts topofbook:getbooktop[rawquote]
7409 665305568
q)count topofbook
482650
q)select from topofbook where sym=`ZSH7, time within (15:24;15:25)
time sym bestbid bestbsize bestask bestasize
----------------------------------------------------------------------
2016.03.15D15:24:32.523259641 ZSH7 911.25 1 911.75 4
2016.03.15D15:24:32.525885003 ZSH7 911.25 1 911.5 4
2016.03.15D15:24:32.529123066 ZSH7 911 4 911.5 4
2016.03.15D15:24:32.540869172 ZSH7 909.5 1 911.5 4
2016.03.15D15:24:32.541712599 ZSH7 909.5 1 911.5 5
..Getting the top of the book here is both slow and extremely memory intensive. It took 634 MB despite rawquote only taking up 80 MB of memory (as we’ll soon see).
Nested lists
Rather than generating book transitions each time we want to make use of them, they can be stored at each point throughout the day. The widebook table provided by TorQ-CME does this by storing the price and size columns as nested lists.
q)select from widebook where sym=`ZSK7, time within (14:56;14:57)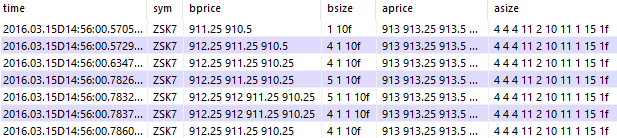
Viewing the Top of the Book (or any number of price levels) is much easier compared to rawquote, and simply requires indexing. Duplicate rows from changes in lower levels can then be removed.
q)\ts topofbook:{tbk:select time, sym, bestbid:bprice[;0], bestbsize:bsize[;0], bestask:aprice[;0], bestasize:asize[;0] from widebook; select from tbk where any differ each (sym;bestbid;bestbsize;bestask;bestasize)}[]
1118 166925936
q)select from topofbook where sym=`ZSK7, time within (14:56;14:57)
time sym bestbid bestbsize bestask bestasize
----------------------------------------------------------------------
2016.03.15D14:56:00.570560918 ZSK7 911.25 1 913 4
2016.03.15D14:56:00.572964041 ZSK7 912.25 4 913 4
2016.03.15D14:56:00.782685277 ZSK7 912.25 5 913 4
2016.03.15D14:56:00.783754680 ZSK7 912.25 4 913 4
2016.03.15D14:56:00.788487833 ZSK7 912.25 5 913 4
..Generating the Top of Book is over 6 times faster and uses 4 times less memory compared to rawquote. Rather than indexing, we could have taken the first element of each nested list. This is more efficient, but indexing is required for viewing other levels.
q)\ts {t:select time, sym, first each bprice, first each bsize, first each asize, first each aprice from widebook; select from t where any differ each (sym;bprice;bsize;aprice;asize)}[]
612 62917280Another common trading metric used when looking at book transitions is to keep track of the Volume Weighted Average Price (vwap) of buying or selling a certain volume of units throughout the day. This calculation can be carried out with ease, having already stored the order book at each point in time.
// Calculates vwap at a particular book snapshot
calcvwap:{[prices;sizes;vol]
$[vol<=last s:sums sizes; / check there is enough volume
(deltas vol&s) wavg prices;
0Nf]
};
q)\ts update buy20vwap:calcvwap'[bprice;bsize;20] from widebook
936 28718464
q)select time, buy20vwap:calcvwap'[bprice;bsize;20], buy100vwap:calcvwap'[bprice;bsize;100], bsize, bprice from widebook where sym=`ZSN6, time within (14:14:49;14:14:50)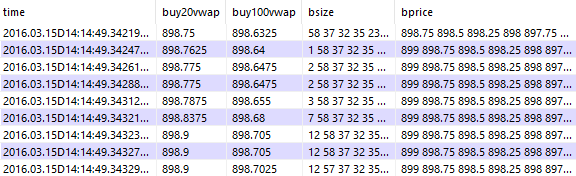
The downside to using widebook is that storing nested lists is costly, with lots of repeated values and bloat. To see this, the objsize function from TorQ’s memusage script can be used to compare approximate in-memory sizes of rawquote and widebook. A detailed explanation of objsize and kdb+ memory allocation can be read about here.
q)objsize rawquote / returns approximate in-memory size in bytes
83886368
q)objsize widebook
451082091The ease of use we gain with nested lists does not come cheap, with over 5 times more memory required than rawquote (430 MB compared to 80 MB). One way of reducing bloat is to separate widebook into bid and ask books.
q)bidbook:bbk where differ 1_'bbk:`time`sym`bprice`bsize#widebook
q)count bidbook
434987
q)askbook:abk where differ 1_'abk:`time`sym`aprice`asize#widebook
q)count askbook
413530
q)objsize[bidbook]+objsize askbook
232763691This saves almost half the memory, although seeing the full order book requires a union or asof join.
Fixed levels
Rather than working with nested lists, another common approach is to store levels of the bid and ask books as fixed columns. This requires splitting the nested lists in widebook.
// Flatten nested lists into separate columns
splitwidecols:{[widebk]
// Fill nested lists with nulls if count is less than 10
bk:update bprice:bprice[;til 10], bsize:bsize[;til 10], aprice:aprice[;til 10], asize:asize[;til 10] from widebk;
// Generate empty table with all 40 price and size columns
cls:raze {raze `$flip enlist[c],enlist(c:x,/:string 1+til 10),\:"size"} each ("bid";"ask");
t:([] time:`timestamp$(); sym:`symbol$());
t:![t;();0b;cls!count[cls]#enlist($;enlist `float;())];
// Flatten and rearrange nested lists in each row
i:raze b,(2*10)+b:a,'10+a:til 10; / indices of bid1, bid1size, ... , ask10size
splitrow:{[i;bk] (bk`time`sym),(raze bk`bprice`bsize`aprice`asize) i};
t upsert i splitrow/:bk
};
q)fixedbook:splitwidecols[widebook]
q)select from fixedbook where sym=`ZSN6, time within (16:48:54.101;16:49)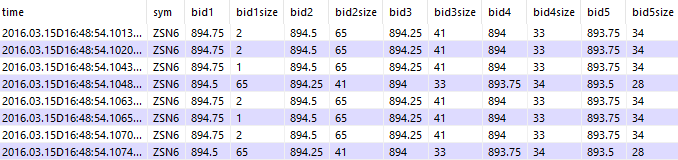
Unlike rawquote and widebook, fixedbook does not allow for unlimited depth. However, removing the need to index into nested lists when viewing specific levels leads to significant reductions in query time and memory.
/ generate top of fixedbook
q)\ts:100 {t:select time, sym, bid1, bid1size, ask1, ask1size from fixedbook; select from t where any differ each (sym;bid1;bid1size;ask1;ask1size)}[]
2162 29361968
/ generate top of widebook
q)\ts:100 {t:select time, sym, b1:bprice[;0], b1s:bsize[;0], a1:aprice[;0], a1s:asize[;0] from widebook; select from t where any differ each (sym;b1;b1s;a1;a1s)}[]
123352 166925936Suppose we had a situation where data is stored using nested lists but lots of queries for the Top of the Book are required. This could be greatly improved by extracting and storing the best bids and asks as separate columns alongside widebook, provided the extra disk space and memory can be afforded.
Calculating the buy and sell vwaps for fixedbook can be done in a similar way as before but a functional select is used this time to save typing out the 20 price and size column names.
// Update fixedbook with buy or sell vwap col
addvwap:{[tab;side;vol]
// Use vector conditional this time but need to fill nulls with 0s
calcvwap:{[prices;sizes;vol]
?[vol<=sum 0^sizes; (deltas vol&sums 0^sizes) wavg 0^prices; 0Nf]
};
// Generate column names
scols:`$(p:string[side],/:string 1+til 10),\:"size";
pcols:`$p;
vcol:`$("buy";"sell")[side=`ask],string[vol],"vwap";
// update calcvwap[(p1;...;p10);(s1;...;s10);vol] from fixedbook
![tab;();0b;(enlist vcol)!enlist(`calcvwap;(enlist,pcols);(enlist,scols);vol)]
};
q)c:`time`sym`sell15vwap`ask1`ask1size`ask2`ask2size`ask3`ask3size
q)c#addvwap[select from fixedbook where sym=`ZSX6, time within (18:19:54;18:20);`ask;15]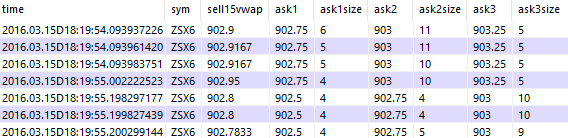
Being able to vectorise operations improves speed over widebook but uses over 10 times more memory.
q)\ts addvwap[fixedbook;`bid;75]
326 276826864
q)\ts update buy75vwap:calcvwap'[bprice;bsize;75] from widebook
1240 25687616How do fixedbook and widebook compare in terms of in-memory sizes? Despite fixedbook having more values (nulls), it requires almost 98 MB less than widebook.
q)objsize[widebook]-objsize fixedbook
102909152This is due to kdb+ allocating memory to simple lists in powers of 2, using a buddy memory allocation algorithm. For a simple list, the memory allocated is given by the number of elements, multiplied by the size of their type, plus 16 bytes overhead. This is then rounded up to the nearest power of 2. For example, in a list of 10 floats we get 10*8+16=96 bytes, which is rounded up to 128.
q)objsize tenfloats:10?10f
128As the time and sym columns are identical in fixedbook and widebook, the difference is coming from the way in which prices and sizes are stored.
Let’s focus on the ask prices. In widebook, each snapshot throughout the course of the day is stored as a nested list. Most (92%) of these nested lists have at least 7 levels, which means they are each allocated 128 bytes. The other 8% are each allocated either 64 or 32 bytes and will still carry some extra overhead, albeit less. Each nested row also carries an 8 byte pointer, with the size of all pointers then being rounded up to the nearest power of 2. The size of the ask prices can be obtained by summing all the nested list sizes, plus the allocated pointer memory.
In fixedbook however, each of the 10 ask price levels are separated into their own columns. Each column consists of a simple list of floats and the size of the column is the size of that simple list rounded up to the nearest power of 2. The size of all ask prices is then approximately the sum of the sizes of the 10 columns.
q)c2:ceiling 0.92*c1:count widebook
q)objsize c2#enlist tenfloats / approximation of 92% of widebook ask prices
107972736
q)objsize 10#enlist c1?10f / approximation of all fixedbook ask prices
83886208With widebook, the extra memory allocated for storing nested lists of prices and sizes amounts to more than the extra needed for storing them separately in fixedbook. This won’t always be true and depends on the number of rows in the book. On disk however, the two tables are of similar size.
| table | disk space (MB) |
| rawquote | 59 |
| widebook | 283 |
| fixedbook | 272 |
Reducing space
While fixedbook and widebook are much easier to work with than rawquote, both in-memory and disk space sizes can quickly become an issue the more quotes we have.
One option to reduce disk space is to use compression. To do this we can compress each column file, leaving the .d file alone as it takes up negligible space. When compressing a nested column, the corresponding # file is not explicitly compressed as kdb+ automatically does this for us.
// Return file paths to table's files given its handle
fp:{[tabh]
if[11h<>type f:key tabh;'badhandle]; / exit if handle isn't to a directory
(` sv tabh,) each f where not f like "*#" / exclude # files
};
// Append 'comp' to table name to create new file path
newfp:{[fileh]
dir:("/" vs string fileh) except enlist ""; / directories making up file path
j:-2+count dir; / index of table name
hsym `$"/" sv @[dir;j;,;"comp"]
};
// Compress table given its handle
compresstab:{[tabh]
// Copy d file
d:first f where (f:fp tabh) like "*.d";
newfp[d] set get d;
// Compress columns with blocks of size 16, gzip level 4
{(newfp x;16;2;4) set get x} each f except d;
};Compressing the 3 tables results in a huge amount of saved disk space, with the overall compression ratio approximately 21:1.
| table | uncompressed (MB) | compressed (MB) |
| rawquote | 59 | 6.7 |
| widebook | 283 | 15 |
| fixedbook | 272 | 7.7 |
Greater compression ratios are obtained for fixedbook and widebook as they contain lots of repetition. The trade off in this case is with speed. To see this, queries to return the Top of the Book were ran 100 times against the wide and fixed books.
| table | uncompressed query time | compressed query time |
| widebook | 00:01:47.168 | 00:02:43.283 |
| fixedbook | 00:00:02.211 | 00:00:10.860 |
Having to decompress the files results in slower performance, particularly for fixedbook. Therefore, it may be useful to leave the Level 1 columns uncompressed if they are regularly queried. For widebook, we could add uncompressed fixed columns for the Top of the Book to the compressed table. Running the query 100 times in this case only took 8 seconds and the new table still remains light on storage, taking up 41 MB of space instead of 15.
Another method of reducing space is to lower the maximum number of price levels that are stored. We will focus on doing this to widebook.
// Cut nested list sizes in widebook
trimwidebook:{[mxlvl;widebk]
// Trim nested list counts to mxlvl
trm:$[1=mxlvl;
{[mxlvl;col] first each col}; / Remove enlisting for single atom
{[mxlvl;col] @[col; where mxlvl<count each col; mxlvl#]}];
tbk:update trm[mxlvl;bprice], trm[mxlvl;bsize], trm[mxlvl;aprice], trm[mxlvl;asize] from widebk;
select from tbk where any differ each (sym;bprice;bsize;aprice;asize)
};
q)select from trimwidebook[3;widebook] where sym=`ZSQ6, time within (08:29:12.6;08:29:13)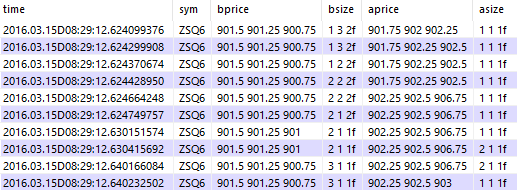
The effect that dropping levels has on row count, memory, and storage can be seen by looking at their new values, as percentages of their totals from widebook.
| max depth | row count % | in-memory % | storage on disk % |
| 1 | 57.1 | 5.1 | 8.1 |
| 2 | 79.3 | 29.2 | 27.1 |
| 3 | 88.1 | 51.6 | 37.8 |
| 4 | 92.2 | 53.6 | 47.6 |
| 5 | 94.6 | 54.8 | 56.8 |
| 6 | 96.1 | 55.5 | 65.8 |
| 7 | 97.2 | 97.2 | 74.4 |
| 8 | 98.3 | 98.4 | 83.1 |
| 9 | 99.5 | 99.6 | 91.9 |
When the max level was taken to be 1, trimwidebook removed the enlisting in each row of the price and size columns. This resulted in saving extra disk space due to no longer requiring # files, and reducing extra in-memory from losing the overhead allocated to each nested row. The other large jumps in-memory occur when increasing to 3 or 7 levels, corresponding to simple list sizes doubling to 64 and 128 bytes, respectively.
The row count percentages tells us that there was a lot of activity in the first few levels. For example, looking at taking only the first 5 levels, we see that we would still keep just under 95% of the rows in widebook. Therefore, by dropping levels 6 to 10 we still retain almost 800,000 book changes, while saving around 45%of both memory and storage. Each extra level after the first 5 adds around 9% more storage on disk but few extra rows.
At first glance, the row counts may seem to suggest that there is limited value in the tail end of the book. However, it doesn’t tell us anything about the activity of these levels in the majority of book transitions, only that it was rare for the maximum level to be the only one that changed. It would be useful to see how many times each level changed independently within widebook.
q)c:exec bsize[;til 10], bprice[;til 10], asize[;til 10], aprice[;til 10] from widebook
q)sum each any (differ each flip@) each c / number of level changes (level 1 first)
482651 338260 234114 167602 137588 101419 73599 66298 57987 42783i| level | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| changes in widebook % | 57.1 | 40.0 | 27.7 | 19.8 | 16.3 | 12.0 | 8.7 | 7.8 | 6.9 | 5.1 |
We can see that activity does indeed tail off the further we go from the Top of the Book. This isn’t surprising given that trades are first executed from the top and these can affect all levels below. Along with the change in row counts, this gives us a clearer picture of the book and can help make an informed decision on how much depth to store.
Summary
While there is no best method of storing depth data, some formats offer significant advantages over others, depending on the use case and memory constraints. In our case, fixedbook turned out to be the easiest and most efficient for analytic purposes but limited the number of price levels. Along with widebook, it required significantly more resources to store than the raw quotes, which are much easier to store in real time.
Compression and removing price levels can offer significant improvements on reducing the resources required for storing large tables of book snapshots. That being said, each data set is different and should be analysed carefully when making choices in both storage format and space reductions. It may be more useful to compress some columns rather than all, and choosing how many levels to drop (if any), may come down to being pragmatic about how much depth is useful. In our analysis, we assumed that the more changes there are, the more useful the data. Knowing the values in the tail end of the book however, may still be useful even if they rarely change and are expensive to store.
In any case, it may be that the most practical option is to store the data in a format that closest matches its source. Different aggregations and formats can then be generated alongside, if and when needed.
Share this:











