TorQ – CME Data Processing Add-on
Data Intellect
Our new addition to the TorQ framework presents a method for processing historical data in its native FIX format from the CME, building and maintaining an order book, and writing this data to disk in a variety of approaches suited to query efficiency or space efficiency. Our example data set is FX futures contracts of 11 major currency pairs, but this method should equally apply to all historical CME market data.
Capabilities
The CME parser is designed to complete the following tasks:
- Parse CME MDP 3.0 FIX messages from both extracted and gzipped files on disk.
- Store these messages as raw Quote, Trade and Security Definition tables (with the raw CME FIX data fields).
- Build an order book from the Quote table with as many levels as the Security Definition states.
- Derive more traditional user-friendly Quote and Trade tables from the above tables.
- Save these tables to disk.
Features of the CME parser:
- The parser is designed to process files as quickly as possible in order for the data to be available quickly after it is published.
- Reads data in from the file in chunks to minimize memory usage while parsing data.
- The codebase is reasonably flexible to small changes in CME specification, in case of updates to the CME MDP format.
- Allows for flexibility on how the data is stored on disk.
- Narrow Book table takes up less space on disk, but has less granularity in the data.
- Wide Book table takes up more space on disk, but can retain more data about the order and state of the book at given time.
- Optionally store raw CME messages as quote, trade and security definition tables on disk.
- The process can be started easily from the command line and passed paths of files in either explicit or wildcard format.
- The process can be monitored by reading log files split into out (information messages), err (Errors) and usage (Inter-process communication).
Limitations:
- The parser can only process raw and gzipped CME MDP 3.0 FIX log files, if the data is compressed in a different format the files will need to be manually decompressed.
- The parser cannot process real time data, it is designed to parse CME FIX MDP 3.0 historical datamine logfiles. If you would like information on how to parse, store and query realtime CME data, please contact AquaQ.
Maintaining the data
The schema for the book maintaining script comes with two options, a “wide book” and a “tall book”. The wide book maintains the full status of the book in every line. his presents a schema which is very easy to query, at the cost of storage space.
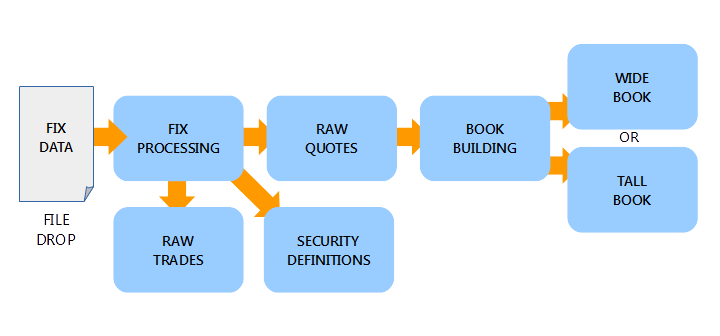
SCHEMATIC OF THE DATA PROCESSING STRUCTURE WITHIN THE FRAMEWORK
In contrast, the tall book stores only what has changed on each update for the appropriate side. The table is thus smaller, since only the level which has been changed (and those below in the case certain updates) on a single side must be changed with each message. Examples on the flags used to switch between processing formats, a sample of the wide book, tall book, a single entry at a single level, and an appropriate query to return a book for a single sym at a certain time are shown on the repo documentation.
Using this add-on to our framework, historical data from the CME can be rapidly and flexibly converted into an easily queried format.
If you’d like to know more, feel free to contact us directly or through or our TorQ group.
Share this:











