kdb+ Feedhandler Development
Data Intellect
Setting up a kdb+ database is relatively straight forward. The TorQ Starter Pack is a good place to start. Two of the trickier bits are:
- Estimating how much memory your dataset will require
- Writing applications (generally called “feedhandlers”) to insert data into the database
For (1) we’ve written previously on some database set up utilities used to estimate the size of a dataset in memory. In truth, it was a bit hard to use (especially if you aren’t a kdb+ developer, shame on you). So instead we’ve created an equivalent spreadsheet version which is also more flexible.
For (2) we’ve created a q process which mimics the interface provided by a standard Tickerplant in a kdb+ set up. However, instead of the usual not-completely-helpful ‘type and ‘length errors, it gives more detailed descriptions of where you have gone wrong. It can be easily run up locally by anyone developing a data ingest application.
The utilities can be found here.
Schema Sizing Spreadsheet
AquaQ’s Schema Sizing spreadsheet allows users to input multiple table schemas and return an estimate of the total memory requirements of the process that will store the tables, for example an RDB in a standard market data capture set up. The spreadsheet requires users to enter table counts, individual column types and average number of values in nested columns. All fields that require user input are coloured yellow for clarity.
The first section requires users to specify bit version; changing the ‘Is 64 Bit’ field to ‘FALSE’ will calculate the memory requirements for a 32 bit system. The bit version has an impact on nested and ‘symbol’ type columns; for a detailed breakdown of memory allocation in kdb+ see here. Users can define table names and the corresponding number of rows expected for the table. Only tables with a row count entered will be included in memory calculations.
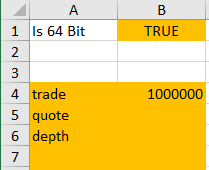
64 bit and table count options
The next section requires the user to enter column names, types, nested counts and also to specify which table the column belongs to.

Column Specifications
Size estimates are automatically calculated for each column dependent on the input. Contained within the workbook is a list of each kdb+ datatype and corresponding byte size. The size of ‘symbol’ type is related to the pointer, and is dependent on the bit version. The size is updated to the appropriate number of bytes when the ‘Is 64 bit’ field is altered. The total size of the database is calculated as the sum of each individual column size. Total size is displayed in both bytes and MB.

Calculation Results
The reliability of the spreadsheet output can be characterised through comparisons to memory calculations directly on the q command line. The following construct reads the memory usage stored in .Q.w before and after the creation of the table and returns the difference.
q)n:1000000
q){s:.Q.w[]`used; trade:([]time:n?.z.p; sym:n?`a`b`c;price:n?100f;size:n?100i;orderid:{16#.Q.a}each til n);.Q.w[][`used]-s}[]
6974886
Testing Feedhandlers
AquaQ’s schemachecker.q script allows a user to write feed handlers in a better test environment. Usually if you write a feed handler and insert it directly to the tickerplant it can throw up hard to comprehend errors with little guidance e.g. ‘type and ‘length. It provides very little information on the issue causing the error. The purpose of this utility is to allow users to build and test feed handlers locally, and to show better errors when something goes wrong, hence allowing easier debugging. The script reads in user-defined table schema from a csv file and builds the specified table. Numerous tables can be defined, for example:
schemaTQ.csv
table,col,coltype,isnested,nestedcount,tablecount
trade,time,timestamp,0,0,1000000
trade,sym,symbol,0,0,1000000
trade,price,float,0,0,1000000
trade,size,int,0,0,1000000
trade,orderid,char,1,12,1000000
quote,time,timestamp,0,0,10000000
quote,sym,symbol,0,0,10000000
quote,ask,float,0,0,10000000
quote,bid,float,0,0,10000000
quote,asize,int,0,0,10000000
quote,bsize,int,0,0,10000000
quote,orderid,char,1,12,1000000Where the nestedcount and tablecount columns are optional. Once the user has defined the schema, the process can be executed using:
q schemachecker.q -schema schemaTQ.csvThe script will default to the 64bit version of kdb+, to set the version as 32bit add the flag -bit64 0 as a command line parameter.
Once the schemachecker.q script has been executed with a defined schema, a user can test .u.upd functions to insert data into the created table and receive a more detailed description of any error in their command. Inserting a data object which fits the schema returns a successful message:
q)meta trade
c | t f a
-------| -----
time | p
sym | s
price | f
size | i
orderid|
q)trade
time sym price size orderid
---------------------------
q).u.upd[`trade;(`a`b;50 100f;200 300i;("abcde";"abcde"))]
insert successful
q)trade
time sym price size orderid
----------------------------------------------------
2017.08.04D09:20:24.052907000 a 50 200 "abcde"
2017.08.04D09:20:24.052907000 b 100 300 "abcde"
However, attempting to insert a data object that does not match the schema will return specific messages. The schemachecker.q script accounts for a number of possible insert errors.
Incorrect simple column type:
q).u.upd[`trade;(`a`b;50 100f;200 300;("abcde";"abcde"))]
col receivedtype expectedtype
------------------------------
size j i
'incorrect type sent
[0] .u.upd[`trade;(`a`b;50 100f;200 300;("abcde";"abcde"))]
Incorrect nested column type:
q).u.upd[`trade;(`a`a;50 100f;200 300i;(8 9;8 9))]
col receivedtype expectedtype
---------------------------------
orderid J C
'incorrect type sent
[0] .u.upd[`trade;(`a`a;50 100f;200 300i;(8 9;8 9))]
Inconsistent nested column type:
q).u.upd[`trade;(`a`b;50 100f;200 300i;("abcde";1 3))]
'nested types are not consistent: +(,`orderid)!,("abcde";1 3)
[0] .u.upd[`trade;(`a`b;50 100f;200 300i;("abcde";1 3))]
Non-typed nested column:
q).u.upd[`trade;(`a`a;50 100f;200 300i;(();()))]
col receivedtype expectedtype
---------------------------------
orderid C
'incorrect type sent
[0] .u.upd[`trade;(`a`a;50 100f;200 300i;(();()))]
Inconsistent (ragged) list lengths:
q).u.upd[`trade;(`a`b`c;50 100f;200 300;("abcde";"abcde"))]
'ragged lists received. All lengths should be the same. Lengths are 3 2 2 2
[0] .u.upd[`trade;(`a`b`c;50 100f;200 300;("abcde";"abcde"))]
Too many or too few columns:
q).u.upd[`trade;(`a`a;50 100f;200 300i)]
'incorrect column length received. Received data is (`a`a;50 100f;200 300i)
[0] .u.upd[`trade;(`a`a;50 100f;200 300i)]
Undefined tables:
q).u.upd[`newtable;(`a`b;50 100f;200 300i;("abcde";"abcde"))]
'supplied table newtable doesn't have a schema set up
[0] .u.upd[`newtable;(`a`b;50 100f;200 300i;("abcde";"abcde"))]
These comprehensive error messages enable the user to easily debug the feed handler by stating the exact nature and location of the problem.
Schema Checker
If the table schema csv file contains the optional nestedcount and tablecount columns, the schemachecker.q script can perform calculations equivalent to those in the Schema Sizing spreadsheet. Users can run the pre-defined .schema.size[] and .schema.sizestats[] functions:
q)// .schema.size[] returns the size of each element within the table
q).schema.size[]
table col coltype isnested expectedtype nestedcount tablecount totalvectorsizeMB
--------------------------------------------------------------------------------------
trade time timestamp 0 p 1 1000000 8
trade sym symbol 0 s 1 1000000 8
trade price float 0 f 1 1000000 8
trade size int 0 i 1 1000000 4
trade orderid char 1 C 12 1000000 39
quote time timestamp 0 p 1 10000000 128
quote sym symbol 0 s 1 10000000 128
quote ask float 0 f 1 10000000 128
quote bid float 0 f 1 10000000 128
quote asize int 0 i 1 10000000 64
quote bsize int 0 i 1 10000000 64
quote orderid char 1 C 12 10000000 433
q)// .schema.sizestats[] returns the overall size of the table
q).schema.sizestats[]
val | totalsizeMB
---------| -----------
quote | 1073
trade | 67
TOTALSIZE| 1140Conclusion
The schemachecker.q script allows users to test feed handlers in a safe and informative test environment, with the option of also providing sizing estimates. It is clear that understanding the ways in which kdb+ allocates memory to certain objects is paramount when setting up a kdb+ database. The user friendly interface of the Schema Sizing spreadsheet allows users to quickly gain an accurate estimate of the size requirements of their database.
Share this:











