Thoughts.
Featured.
Featured.
-

March Madness
Read MoreMarch has now Marched on into April - spring has sprung and so have we. It's warming up and the evenings are getting brighter, so we've…
-

Getting Creative: Putting, Painting, Pancaking
Read MoreAnother recap of the social activities at AquaQ - this past month we've been releasing our inner artists and had a few friendly competitions.
-

Cakes, Cues and Karts
Read MoreThis November was jam packed with events: from cakes to go-karts there was something for everyone!
-
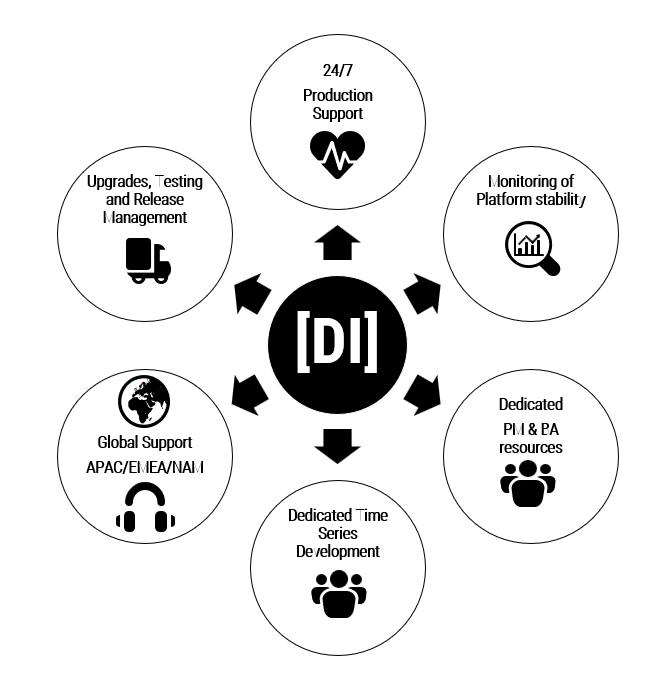
Managed Services with Data Intellect
Read MoreA full kdb+ Managed Service, enabling clients to focus on their business. It is powered by our industry partnerships, thought leadership, technology and data expertise.
Thoughts.

Project Redshift
Data Intellect have wrapped up their Redshift Project, investigating integrating kdb+ with Amazon's datawarehousing solution
Read More
ARK 3: Software Development Life Cycle
A software development lifecycle (SDLC) is the process of getting a piece of software designed, created and deployed to production in such a way that it…
Read More
Simplifying Software Development with Containers
An applied introduction to containers, implementation, and their place in a modern software development life cycle.
Read More
kdb+ is Memory Hungry, Right?
A look at how kdb+ uses memory and what can be done to optimise or reduce the memory footprint
Read More


International Women’s Day 2024
Celebrating International Women's Day around the company joined by some special guests in the Belfast office!
Read More


Data Creep: The Uninvited Guest in Your Database
I wish I was special, I don't belong here
Read More
