Automating Data Egress from kdb+ into Google BigQuery
Data Intellect
kdb+ tick data capture software has been largely popular in banks, hedge funds and other financial institutions for years. Its kdb+ framework permits incredibly fast querying of data largely due to its vectorised querying language and efficient storage methods. A large cost component in any kdb+ implementation is always storage costs. Storage costs have been a big driving factor towards the large scale Cloud technology investigation that the industry is currently undergoing. It is not uncommon for users to have to downsize, aggregate or outright delete their data just to fit within a storage budget.
AquaQ Analytics previously presented a kdb+/Python API that allows for the querying, extracting and converting of data from Google’s BigQuery into kdb+. The warm reception that this received has led to development into what we deem to be the second half of the solution – an automated system to push the data from kdb+ to BigQuery. This new software piece should allow for a complete Cloud ecosystem to be pinned to a user’s existing tick capture system and allow fully for the disk-hot/Cloud-warm storage solution.
Note that users can also ignore this export step for market data and integrate directly with Refinitiv’s Tick History store in BigQuery.
The Data Journey
The kdb+ tick setup for data capture and storage varies vastly between different firms and companies, but the underlying framework is largely similar everywhere. This means that the systems typically all comprise of the same processes with comparable functionality. One of the most fundamental of these processes is the HDB process which is used to connect to a user to their historical data. As the runtime of the system progresses, some of the processes, principally the on-disk HDB, have the potential to grow in size and utilise a large amount of storage. There are two problems with this model: scalability and costs. Servers do not have the capability to automatically demand more storage space if a HDB grows too large to fit in the current allotment. As well as this, the cost of standard storage (whether standard SSD or otherwise) can be high.
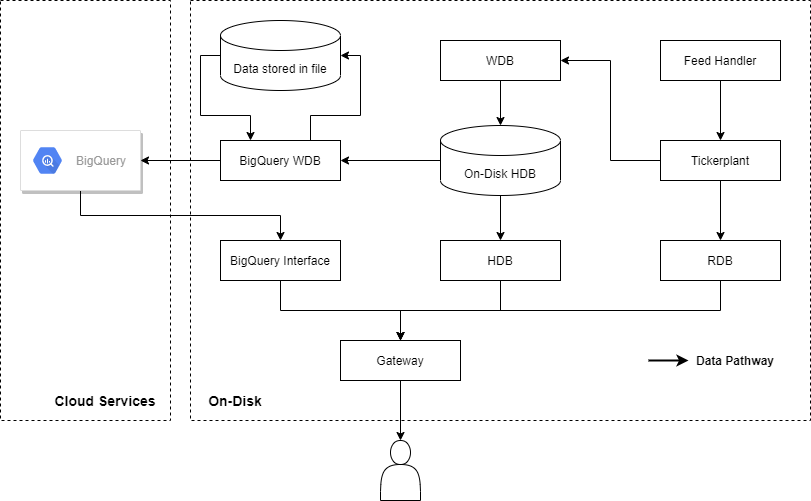
The proposed model ventured by AquaQ Analytics is that users would perform some kind of internal analysis on the system to work out what data is most frequently accessed and decide a cut-off point (this could be thirty days, it could be four years depending on the size of the system and frequency of access). The newly developed Cloud write down process, henceforth referred to as the BigQuery Write Database (BQ WDB), will then push the data to Google BigQuery for the user automatically. Once a partition of data is safely pushed to BigQuery the data for that partition in the HDB will be deleted and the data-access gateway, as described in the previous post, will target BigQuery for the data. On top of this, the push of data is completely configurable to the user: for example, if a user does not want any write-down occurring on weekdays, the user can specify what days and times suit them for the write-down to occur.
The write-down occurs via an intermediary file. Data living within a kdb+ HDB cannot be directly pushed up to BigQuery due to data-type mismatches and splayed data files. The data is therefore pulled from the HDB into the BQ WDB process, translated to appropriate data-types and written to a file, which is then pushed as a whole to BigQuery. The obvious question to follow is surrounding which file type is best? Google encourages the use of the file types such as Parquet and Avro due to their column-orientated data structure with in-built schemas. This leads to fast data reading due to ease of parallelisation. AquaQ Analytics already offers a kdb+ Parquet library (for which there is a blog about here) that offers read and write functionality – as such, this was the chosen format. It was also chosen to make use of some of the more simple formats for users who do not have access to the required C libraries to perform the Parquet write-down. For example, the CSV file format is available to users, however, users would typically see a reduction in write performance when using this file format (this will be seen in a later section).
Data Types
One consideration associated with the hybrid solution, is one of differing datatypes. The datatypes associated with kdb+ and Google BigQuery do not align for a lot of the cases that are needed. As a result of this, storing data types in different formats has proven to be the most viable method that has been explored.
An example of this is the kdb+ timestamp. The kdb+ temporal type contains up to nanosecond precision, whereas the BigQuery TIMESTAMP data-type (which is visually the most similar) only deals with precision up to the microsecond scale. For users who don’t require sub-microsecond granularity this wouldn’t be a problem, however this is not an assumption that can be safely made. The decision made on this issue is one to sacrifice visuality within BigQuery, i.e. kdb+ timestamps are stored as BigQuery INT64s. This keeps the full precision available to the user, which, after all, is the most important thing. This is not something that should scare a user, as both the BQ WDB and BigQuery Interface processes automatically handle the data translation so users do not have to think about translating data themselves at any point. The data translation when pulling data back into kdb+ is mainly manipulated by configuration files and offers a wide range of data casting options. A full list of complimentary datatypes is presented in the table below.
| kdb+ Datatype | BigQuery Datatype | Note |
|---|---|---|
| boolean | BOOLEAN | The boolean datatype in kdb takes the form of either 0 or 1b, whereas, in BigQuery, the BOOLEAN is either false or true respectively. Users can be assured that both are 1 byte in size, so no increased memory consumption is associated between the two types. |
| guid | STRING | BigQuery does not have a type that is similar to that of a guid. As such, the STRING type was chosen as it is easy to transfer an inbound string to a guid when retrieving the data. |
| byte | BYTE | |
| short | INTEGER | |
| int | INTEGER | |
| long | INTEGER | |
| real | FLOAT | |
| float | FLOAT | |
| char | STRING | |
| symbol | STRING | Both symbol and char types are associated with a STRING type. This is handled automatically for the user upon querying the data. |
| timestamp | INTEGER | Integer representing nanoseconds since the start of 1970. |
| month | INTEGER | Integer representing the number of months since 1970.01. |
| date | DATE | |
| datetime | INTEGER | Integer representing the number of milliseconds since the start of 1970. |
| timespan | INTEGER | Integer representing the number of nanoseconds since 0D00:00:00.000000000. |
| minute | INTEGER | Integer representing the number of minutes since 00:00. |
| second | INTEGER | Integer representing the number of seconds since 00:00:00. |
| time | TIME | 00:00:00.000 in kdb+ to 00:00:00.000000 in BigQuery. |
There remains one precision discrepancy associated with the time/TIME datatype pair, however this is not an issue as the kdb+ time type is only to three decimal places, while the BigQuery TIME datatype is to six. Therefore, any data being pushed from a kdb+ HDB to BigQuery will not lose any precision.
Performance
An investigation into the write-down of data from the HDB to Google BigQuery was undertaken for both the Parquet and CSV intermediaries. The process as a whole can be split into three sub-processes: the write-to-file, the write-to-database and the data deletion functionalities. The write-to-file sub-process absorbs all HDB data capture, data translation and write-to-file obligations of the process. The write-to-database part of the process is what takes the file, pushes to BigQuery and awaits confirmation of the data being received. Data deletion comprises of deleting the data file once it has been pushed, and once a full partition has been pushed, making sure the gateway targets BigQuery for the data and then deleting the partition from the HDB.
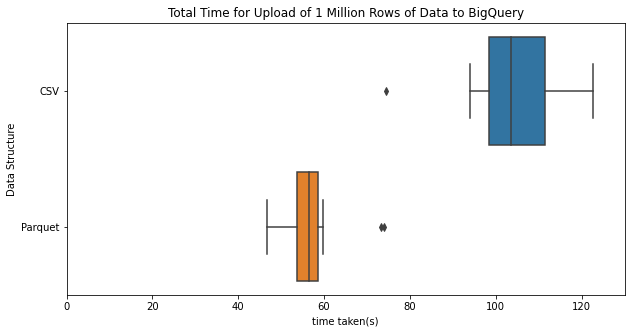
The whole process can be summarised by the above box plot showing the time taken for 1 million rows to be pushed to BigQuery for both the CSV and Parquet file types. The write-down as performed for the statistics in this section were performed from home, pushed to the AquaQ Analytics server a few miles away, and then pushed to the US where the data is stored. The data location has not been investigated with relevance to performance here, but potentially one could see an improvement by picking a closer data centre (which is an easily configurable option).
Above it is seen that the Parquet file type significantly outperforms the CSV file type taking nearly half the time. This mass alteration in times can largely be solved by looking at the files themselves. One million rows of the kdb+ HDB data takes up about 45 MB of data for the table being pushed here. Once converted to a CSV file this number grows to about 52 MB of data. The Parquet file format itself is one that is compressed; as such, it significantly reduces the size of the file being pushed and is only about 17 MB of data. A large overhead of the timings here is the push of the data packet to BigQuery and this is one of the main reasons why Parquet excels over CSV. This is seen in the plot below which shows solely the times taken to push the data to BigQuery.
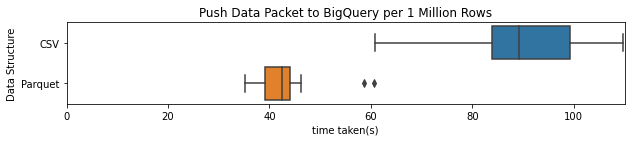
The other significant timings largely spawn from the time taken by BigQuery to read in the data. The time taken to read the files was indeed quicker for the Parquet data file over the CSV file. It is observed in the associated plot below that the difference is not as significant as one might expect. This is, however, based upon the one file size, further investigation could be undertaken in order to see whether the number of rows changes performance.

A more in depth investigation into the “BigQuery Time” was performed by B. Komarniczky for a blog which included the addition of an Avro file format and a compressed CSV with the GZIP algorithm format. The additional timings are results of the other parts of the sub-processes such as the waiting for confirmation of successful push from BigQuery and the writing of the HDB data to file. The timings associated with the other sub-processes are not as significant as the previous mentioned parts of the process.
Conclusion
In a world where data is everything, the downsizing, aggregating and deleting of data is the furthest thing that a company wants to do. This BQ WDB process paired with the BigQuery Interface is a method in which users can take advantage of low storage costs and can begin migration to the Cloud. The Cloud can facilitate the pay as you go model instead of the pay what you may require. With significantly cheaper storage costs as well, the potential savings could be large.
The software discussed here is a flexible piece of tooling that allows users to move their data to the Cloud at their own pace. Users can decide whether to remain with a kdb+ heavy storage system or try the opposite and move to a largely Cloud based set-up (and obviously, anywhere in-between). Where the data sits is at the application developers’ discretion.
AquaQ Analytics are really excited about the future progression of both the BigQuery interface and BigQuery Write Database as it is a data storage solution that we really believe can be advantageous to a lot of current clients and prospective clients. Please feel free to leave a comment or send an email to info@aquaq.co.uk for any more information.
Share this: